在开始之前
这个系列的概要
这个系列主要是讲Java-IO,分为上中下三篇。
- 上篇主要是介绍Java原生的BIO(IO),NIO,AIO(NIO2)
- 中篇主要是介绍经典的IO框架Netty的基本概念,以及线程模型
- 下篇则是讲Netty的项目实践,如何用Netty实现一套RPC框架
关于源码
在介绍Java原生IO,以及Netty框架的时候,我都会以一个简单的HttpServer作为Demo。
所以在本系列中会包含四个版本的HttpServer(BIO,NIO,AIO,Netty)。
其中BIO,NIO,AIO版本的Demo未引入任何第三方包,只需要JDK8+即可运行。
Netty版本的Demo需要配置第三方依赖,对应的maven配置在中篇会单独列出。
快速开始
本篇主要是对Java原生IO(BIO、NIO、AIO)进行介绍,同时进行对比。
为了给大家一个直观快速的感受,我们分别用这几种不同的IO方式,来写一个简单的HttpServer,这个HttpServer的主要功能就是,将浏览器的请求内容,原封不动的返回给浏览器。可能代码里面的部分API大家可能已经忘记了,不过不要紧,后面会对比较重要的部分进行详细的讲解。
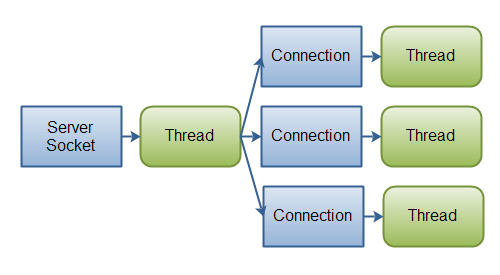
BIO版本HttpServer
Java的BIO(IO)很简单,直接面向socket编程,每当接收到一个新的socket,都新建一个线程进行处理。当然了,处理线程也可以设计成线程池,可以在一定程度上提高性能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public class BioHttpServer {
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newFixedThreadPool(10);
ServerSocket serverSocket = new ServerSocket(8081);
while (!Thread.interrupted()) {
final Socket accept = serverSocket.accept();
executor.submit(() -> {
try (InputStream inputStream = accept.getInputStream();
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(accept.getOutputStream()))) {
byte[] bytes = new byte[inputStream.available()];
inputStream.read(bytes);
writer.write(ResponseUtils.getResponse(new String(bytes, StandardCharsets.UTF_8)));
writer.flush();
accept.shutdownInput();
accept.shutdownOutput();
accept.close();
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
}
|
NIO版本HttpServer
NIO是本章重点介绍内用,因为是对后续的Netty框架介绍做铺垫,所以这里会讨论以下内容:
- Channel
- Buffer
- Selector
- 为什么用NIO
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| public class NioHttpServer {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.socket().bind(new InetSocketAddress(8082));
ssc.configureBlocking(false);
ssc.register(selector, SelectionKey.OP_ACCEPT);
while (!Thread.interrupted()) {
if (selector.select() > 0) {
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isAcceptable()) {
ServerSocketChannel serverSocketChannel = (ServerSocketChannel) key.channel();
SocketChannel channel = serverSocketChannel.accept();
channel.configureBlocking(false);
channel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel sc = (SocketChannel) key.channel();
ByteBuffer result = ByteBuffer.allocate(102400);
ByteBuffer buffer = ByteBuffer.allocate(10);
while (sc.read(buffer) > 0) {
buffer.flip();
result.put(buffer);
buffer.clear();
}
sc.register(selector, SelectionKey.OP_WRITE, new String(result.array(), StandardCharsets.UTF_8));
} else if (key.isWritable()) {
SocketChannel sc = (SocketChannel) key.channel();
String attachment = (String) key.attachment();
ByteBuffer buffer = ByteBuffer.wrap(ResponseUtils.getResponse(attachment).getBytes());
while (buffer.hasRemaining()) {
sc.write(buffer);
}
sc.close();
}
}
}
}
}
}
|
思考1:阻塞和同步是一个概念吗?非阻塞=异步?
这种概念性的问题没必要太关注,有点像回字有多少种写法,关键的还是要能够理解IO模型的原理。
这里只是简单提一下。通过Unix的五种IO模型介绍 我们可以知道:
1.BIO是阻塞式IO,是同步IO,这点是没有异议的
2.NIO可以设置两种模式:阻塞模式(Unix多路复用IO)和非阻塞模式(Unix非阻塞IO),但数据从内核态加载为用户态的这个过程,是同步的,所以NIO也是同步的。
3.AIO(后面会进行讨论)是完全的非阻塞模式,也是真正的异步IO。
综上:
非阻塞,对于底层Unix-IO模型,都是指数据从磁盘加载到内核态的这个过程,是否阻塞。
异步是指整个IO操作(包含了两步:数据在内核态准备完成,数据从内核态转变为用户态)完成之后,系统通知应用程序(通过signal或callback)。
思考2:为什么从buffer读数据要先进行flip操作
buffer底层就是一个数组,我们需要当写数据的时候我们需要记录从何处开始写(position),以及数组的最大容量(capacity)。
当我们读数据的时候,需要知道当前数组有多少个元素可读(limit),以及记录当前已经读到了哪个位置(position)。
所以当读写模式转换的时候,我们就需要对buffer进行flip(写转读),clear(读转写)操作。详见【NIO Buffer】章节
以上只是一般性操作,不代表所有应用场景。
思考3:为什么向buffer写数据要先进行clear操作(新建的buffer不需要)
同思考2
NIO Channel
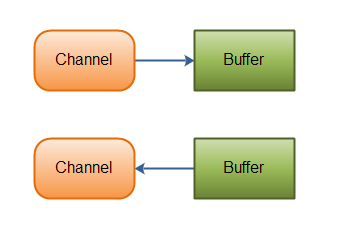
channel在NIO中的地位,和流在BIO中的地位类似。但有以下不同点:
| 区别 |
Channel |
流(InputStream,OutputStream) |
| 方向 |
双向的 |
一般来说都是单向的 |
| 异步 |
支持异步操作【AIO就是典型的例子】 |
只支持同步操作 |
| 对接 |
一般不能直接从channel读写数据,channel只和缓冲区Buffer交互 |
直接对流进行读写 |
NIO Buffer
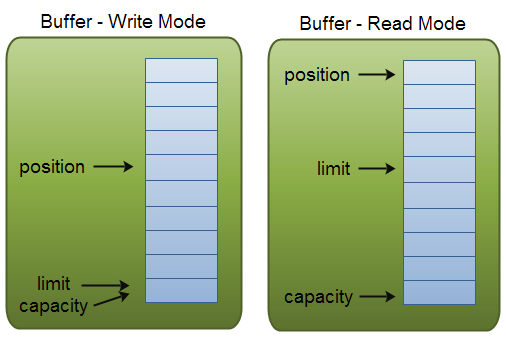
|
向缓冲区写数据时 |
从缓冲区读数据时 |
| position |
记录当前已经在buffer中写入了多少数据,指向下一个即将写入数据的坑位。举例,如果当前从缓冲区读取7个元素,则当前缓冲区的position的值为7,指向第8个元素的位置。 |
记录当前从buffer中读取了多少数据,指向下一个即将读取的元素。举例,如果当前已经从缓冲区读取了4个元素,那么缓冲区的position将被设置为4,指向第5个元素。 |
| limit |
一般来说limit等于capacity。 |
记录最后一个可读取元素的位置。 |
| capacity |
表示缓冲区的最大容量。 |
表示缓冲区的最大容量。 |
有一篇文章对buffer内部结构的介绍很详细,可以参考:IBM-NIO入门
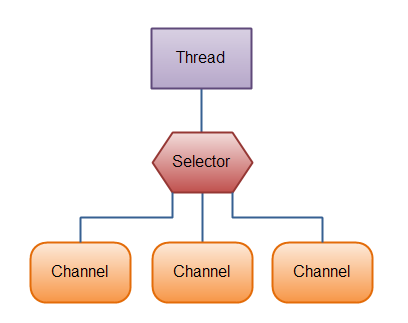
NIO Selector
Selector基于操作系统底层的epoll,一个Selector可以同时监听多个Channel上的事件,不必对每一个连接都新建一个线程。
为什么使用NIO
NIO 的创建目的是为了让 Java 程序员可以实现高速 I/O 而无需编写自定义的本机代码。NIO 将最耗时的 I/O 操作(即填充和提取缓冲区)转移回操作系统,因而可以极大地提高速度。
NIO的出现,使得当IO未就绪时,线程可以不挂起,继续处理其他事情。一个线程也不必局限于只为一个IO连接服务。
BIO与NIO的线程模型对比:
| BIO模型 |
NIO模型 |
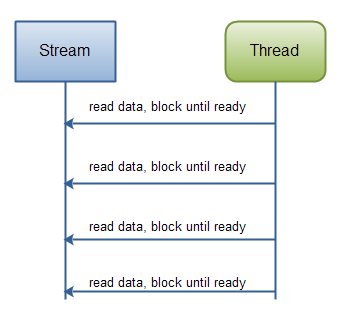 |
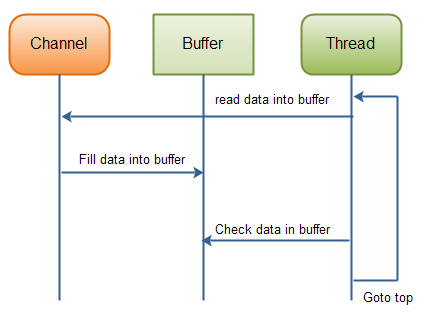 |
| IO以流的方式处理数据 |
NIO 以块的方式处理数据 |
| 面向流的IO系统一次一个字节地处理数据,通过过滤器,处理流程很优雅 |
每一个操作都在一步中产生或者消费一个数据块,缺少流式处理的优雅性与简单性 |
| 面向流的IO通常相当慢 |
按块处理数据比按流处理要快得多 |
AIO版本HttpServer
应用程序完全不用关心IO何时准备好,这一切都交给操作系统(IO的两个阶段)。
同时给操作系统提供一个缓冲区,当数据往缓冲区写好之后,通知应用程序即可。
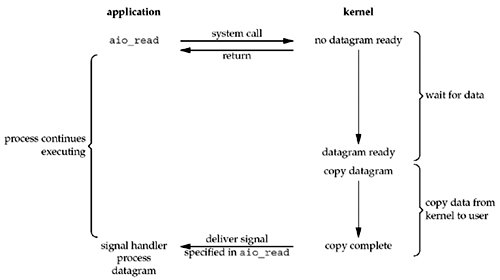
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| public class AioHttpServer {
public static void main(String[] args) throws Exception {
final AsynchronousServerSocketChannel channel = AsynchronousServerSocketChannel.open().bind(new InetSocketAddress(8083));
channel.accept(channel, new CompletionHandler<AsynchronousSocketChannel, AsynchronousServerSocketChannel>() {
@Override
public void completed(final AsynchronousSocketChannel client, AsynchronousServerSocketChannel attachment) {
attachment.accept(attachment, this);
ByteBuffer buffer = ByteBuffer.allocate(1024);
client.read(buffer, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result_num, ByteBuffer attachment) {
attachment.flip();
byte[] body = new byte[attachment.remaining()];
attachment.get(body);
String response = ResponseUtils.getResponse(new String(body, StandardCharsets.UTF_8));
ByteBuffer writeBuffer = ByteBuffer.wrap(response.getBytes());
client.write(writeBuffer, writeBuffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
try {
client.close();
} catch (IOException e) {
}
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {}
});
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {}
});
}
@Override
public void failed(Throwable exc, AsynchronousServerSocketChannel attachment) {}
});
System.in.read();
}
}
|
思考1:accept again,why?
因为AIO是异步模型,当接收到请求之后,当前线程就退出了,所以当接收到请求之后,需要再次注册服务端的accept操作。
思考2:read数据之前,先分配缓冲区,这样有什么缺点
预分配缓冲区大小,需要按照最大请求的输入Body-size进行分配,所以对于一个Body比较小的请求,相当于资源浪费。
追加思考:如果预分配的缓冲区大小不足以接收channel中的所有数据,怎么办?
数据在Channel中是顺序读取的,如果接收数据的Buffer空间,小于Channel中实际的数据内容,比如,现在Channel中有4个字节[a,b,c,d],但现在接受缓冲区数据的Buffer大小只有3个字节。
此时,只会读取前Channel中的前三个字节[a,b,c]到Buffer中,剩余的一个字节[d]仍留在Channel中,如果继续从Channel中读数据,可以将第四个字节读出来。
最后:如果Channel中有数据未读取,当Channel关闭的时候,里面的数据就被丢弃了。
由此我们可以看出:
java.nio.channels.AsynchronousSocketChannel#read(java.nio.ByteBuffer, A, java.nio.channels.CompletionHandler<java.lang.Integer,? super A>)
这个方法,以下两种情况满足任意一种都会认为数据读取完成,从而回调completed方法:
1.channel中的所有数据都已经读到Buffer中。
2.Buffer的可用空间已经被填满。
思考3:System.in.read(); 这行代码的必要性
因为异步代码执行完成之后,线程就退出了,随之应用程序退出。
所以需要加上一行,主线程等待系统输入,避免程序退出。
AIO看起来比NIO更高效,为什么Netty使用NIO而不是AIO?
1.服务器大多是Linux系统,AIO的底层实现仍使用EPOLL,没有很好实现AIO,因此在性能上没有明显的优势。
2.AIO接收数据的时候需要预先分配缓冲区大小, 而不是NIO那种需要接收时才需要分配缓存, 所以对连接数量非常大但流量小的情况, 会造成内存浪费
以上代码中用到的工具类
主要就是封装Http-Header和Response
1
2
3
4
5
6
7
8
9
10
11
12
| public class ResponseUtils {
private final static String CRLF = "\r\n";
public static String getResponse(String msg) {
msg = "Server response:<br><br>" + msg.replaceAll(CRLF, "<br>");
return new StringBuilder("HTTP /1.1 200 ok ").append(CRLF)
.append("Content-Type:text/html ").append(CRLF)
.append("Content-Length:" + msg.length()).append(CRLF).append(CRLF)
.append(msg).toString();
}
}
|
他山之石
没有比这个更简明易懂的NIO教程了
Java NIO Tutorial
IBM讲NIO的Buffer比较详细
IBM-NIO入门
AIO讲解
在 Java 7 中体会 NIO.2 异步执行的快乐