事务-概览
简介
事务是什么?
事务不是一个天然存在的东西,它是被人为创造出来,目的是简化应用层的编程模型。
有了事务,应用程序可以不用考虑某些内部潜在的错误以及复杂的井发性问题,这些都可以交给数据库来负责处理,我们称之为安全性保证。
即:事务是一种数据安全性保证的机制。
安全性保证
| 分类 | 说明 | 备注 |
|---|---|---|
| 原子性( Atomicity) | 在出错时中止事务,并将部分完成的写入全部丢弃 | 处理异常 |
| 一致性( Consistency) | 本质上要求应用层来维护状态一致(或者恒等) | |
| 隔离性( Isolation) | 并发执行的多个事务相互隔离,它们不能互相交叉 | 处理并发 |
| 持久性( Durability) | 一旦事务提交成功,即使存在硬件故障或数据库崩溃,事务所写入的任何数据也不会消失 |
原子性,隔离性和持久性是数据库自身的属性,而 ACID中的一致性更多是应用层的属性。
应用程序可能借助数据库提供的原子性和隔离性,以达到一致性,但一致性本身并不拥于数据库。
因此,字母C其实并不应该属于【事务的安全性保证】。
事务隔离级别分类
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|---|
| 无隔离 | 读未提交(Read uncommitted) | 可能 | 可能 | 可能 |
| 弱隔离 | 读已提交(Read committed) | 不可能 | 可能 | 可能 |
| 弱隔离 | 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 强隔离 | 串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
Q:读未提交(Read uncommitted)存在的意义是什么?
A:1.防止脏写(下面会讲到);2.保证原子性(发生错误可以回滚)
读-未提交
读未提交可以提供以下保证:
写数据库肘,只会覆盖已成功提交的数据(防止“脏写”)
首先来看一个【脏写】的示例:
买车的时候,需要同时更新【车辆,发票】。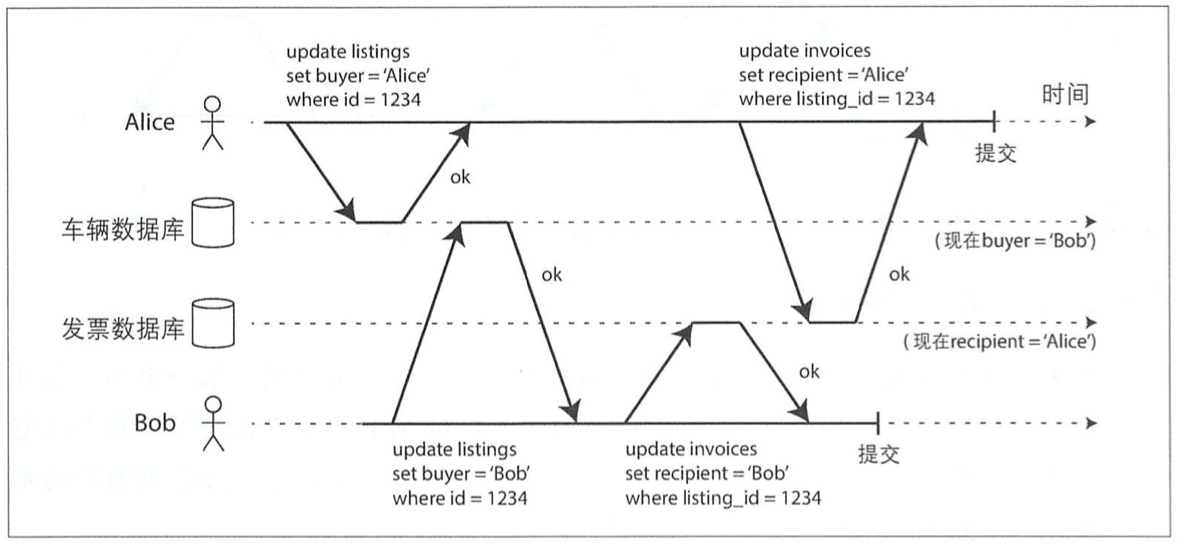
该例最终会导致:Alice拥有发票,Bob拥有车辆。
而【读-未提交】可以避免该问题。
读-提交
读-提交是最基本的的事务隔离级别,它只提供以下两个保证 :
读数据库肘,只能看到已成功提交的数据(防止“脏读”)。
写数据库肘,只会覆盖已成功提交的数据(防止“脏写”)。
【防止脏写】上面我们已经介绍过了,结下来看一下【防止脏读】:
举例:用户2只有在用户1的事务提交之后才能看到x的新值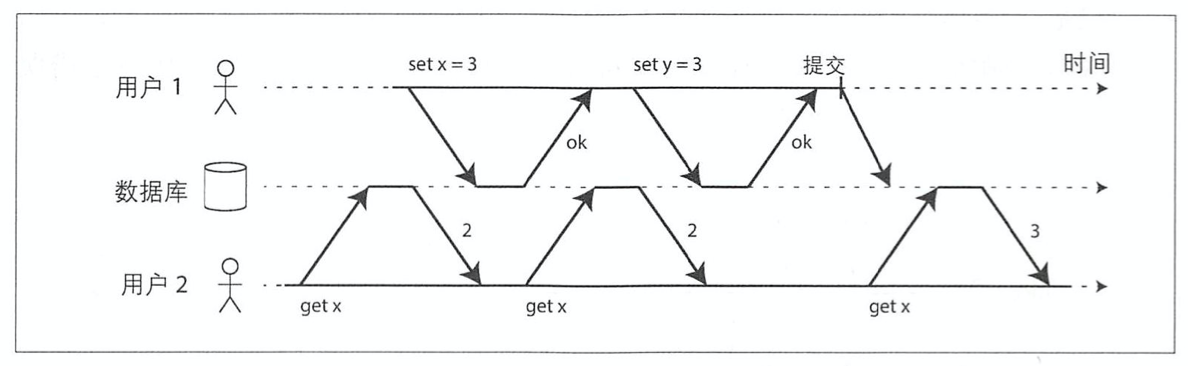
实现读-提交
| 实现方式 | 说明 | 推荐 |
|---|---|---|
| 行锁 | 修改记录需要获取锁 读取记录需要获取锁 |
不推荐 因为有可能写事件很耗时,导致读事件长期排队 |
| 多版本 | 对于每个待更新的对象,数据库都会维护其旧值和当前持锁事务将要设置的新值两个版本。 在事务提交之前,所有其他读操作都读取旧值;仅当写事务提交之后,才会切换到读取新值。 |
推荐 性能更优,只读事务不受写事件影响。 |
Q1:多版本需要锁吗?
A1:需要
Q2:通过行锁可以达到上图所示的效果吗(第二次get x 能获取到 2 吗)?
A2:不能(因为用户1在进行set x=3时,拿到了x的锁,此时用户2的第二次get x,读操作拿不到锁,会被阻塞)
可重复读(快照隔离)
如何定义可重复读?
两次读取同一个对象,读到的结果一致?片面
首先举一个不可重复读的例子: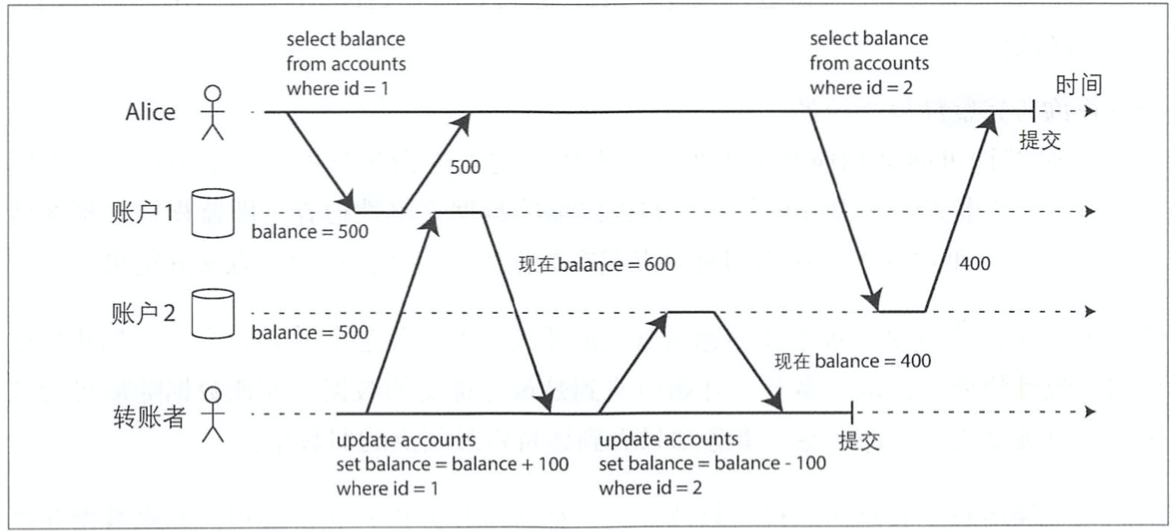
假设Alice在银行有1000美元的存款,分为两个账户,每个500美元。
现在有这样一笔转账交易:从账户1转100美元到账户2。【可以理解为定投100到理财账户】
如果在她提交转账请求之后,而银行数据库系统执行转账的过程中间,来查看两个账户的余额,她有可能会看到账号2在收到转账之前的余额(500美元),和账户1在完成转账之后的余额(400美元)。
对于Alice巳来说,貌似她的账户总共只有900美元,有100美元消失了。
这种异常现象被称为不可重复读取(nonrepeatable read)或读倾斜(read skew)。
可重复读就是为了解决这种问题。
实现可重复读(快照级别隔离)
快照级别隔离的实现通常采用写锁来防止脏写(参阅前面的“实现读-提交”),这意味着正在进行写操作的事务会阻止同一对象上的其他事务。
但是,读取则不需要加锁。
从性能角度看,快照级别隔离的一个关键点是读操作不会阻止写操作,反之亦然。
如果只是为了提供读-提交级别隔离,而不是完整的快照级别隔离,则只保留对象的两个版本就足够了:一个己提交的旧版本和尚未提交的新版本。
所以,支持快照级别隔离的存储引擎往往直接采用MVCC来实现读提交隔离。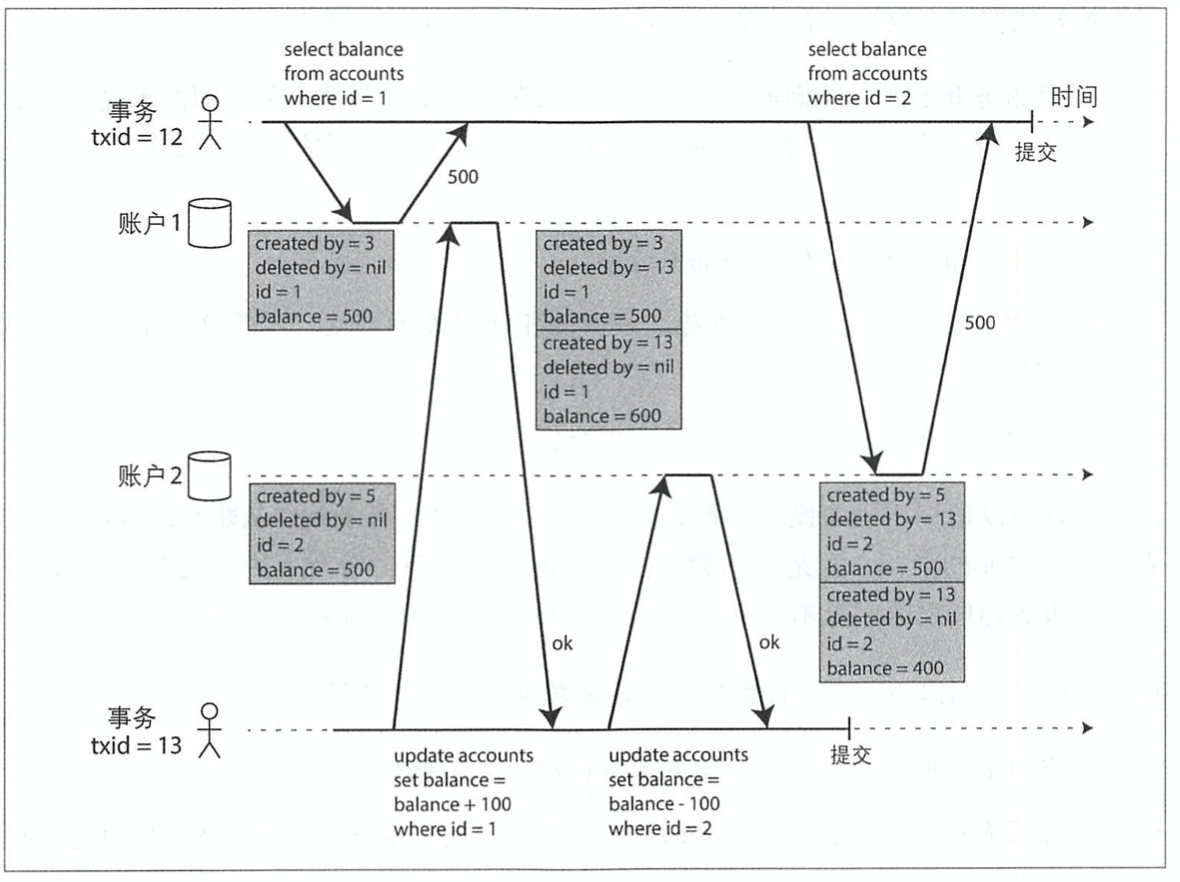
一致性快照的可见性规则
通过上图我们可以看出,事务读数据库时,通过事务ID可以决定哪些对象可见,哪些不可见。
当以下两个条件都成立,则数据对象对事务可见:
1.事务开始的时刻,创建该对象的事务已经完成了提交。
2.对象没有被标记为删除;或者即使标记了,但删除事务在当前事务开始的时刻还没有完成提交。
可以看出,在事务的开始时刻就已经确定了哪些对象可见,哪些不可见。
串行化
举例:医院值班室需要保证至少要有1人在岗,现在A和B都在值班室,他们都认为现在有两个人在,自己下班后,还有另一个人在值班室,满足值班室最低1人在岗条件。所以他们都发起了下班请求: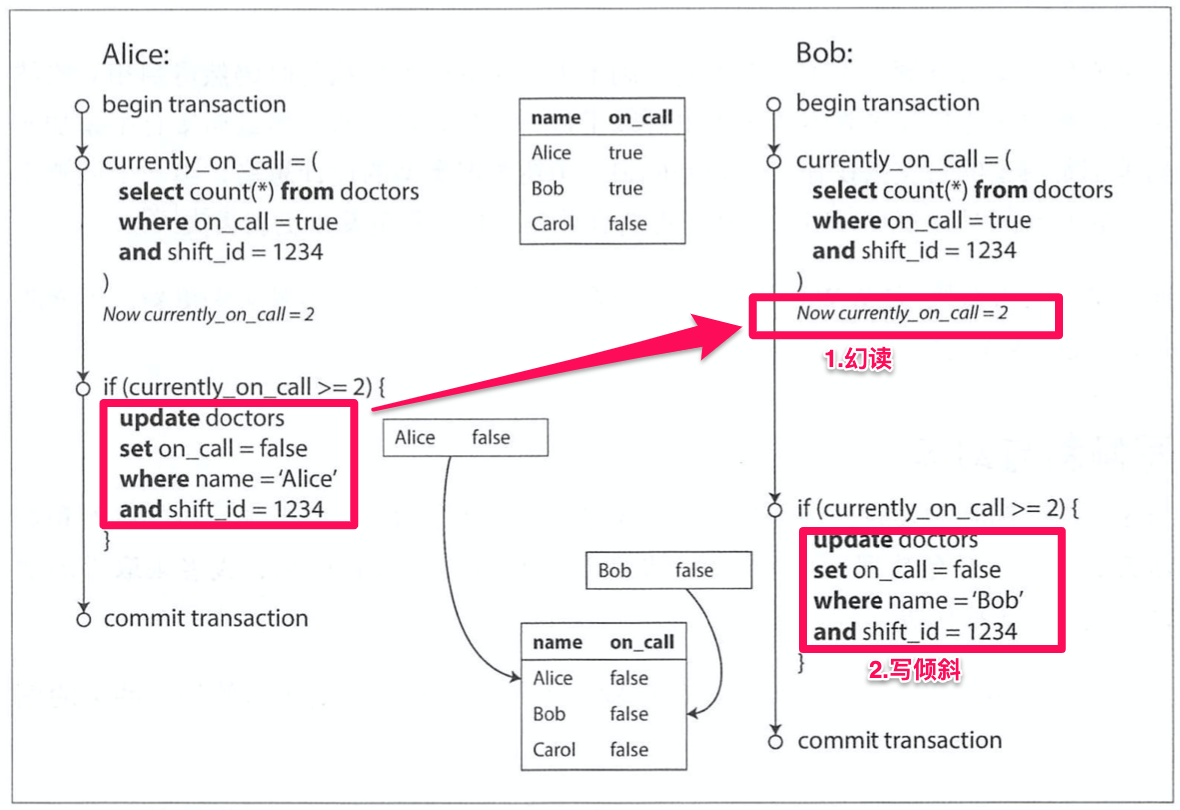
定义
幻读:在一个事务中的写入改变了另一个事务查询结果的现象。(从隔离性的角度来说,这种改变确实是不应该被感知到的)
写倾斜:事务首先查询数据,根据返回的结果而作出某些决定,然后修改数据库 。当事务提交时,支持决定的前提条件已不再成立。
串行化实现方案
| 方案 | 说明 |
|---|---|
| 严格串行执行 | 如果每个事务的执行速度非常快,且单个CPU核可以满足事务的吞吐量要求,严格串行执行是一个非常简单有效的方案。 |
| 两阶段加锁 | 几十年来,这一直是实现可串行化的标准方式,但还是有很多系统出于性能原因而放弃使用它。 |
| 可串行化的快照隔离 (SSI) | 一种最新的算法,可以避免前面方法的大部分缺点。 它秉持乐观预期的原则,允许多个事务并发执行而不互相阻塞。 仅当事务尝试提交肘,才检查可能的冲突,如果发现违背了串行化,则某些事务会被中止。 |
1.严格串行执行(Redis为代表)
解决井发问题最直接的方法是避免井发:即在一个线程上按顺序方式每次只执行一个事务。
串行执行小结当满足以下约束条件时,串行执行事务可以实现串行化隔离:
事务必须简短而高效,否则一个缓慢的事务会影响到所有其他事务的执行性能。
仅限于活动数据集完全可以加载到内存的场景。有些很少访问的数据可能会被移到磁盘,但万一单线程事务需要访问它,就会严重拖累性能。
写入吞吐量必须足够低,才能在单个CPU核上处理,否则就需要采用分区,最好没有跨分区事务。
跨分区事务虽然也可以支持,但是占比必须很小。
单线程不能利用多核CPU,这种方案一般不考虑!
Q:Redis多分片场景下,支持事务吗? N
2.两阶段加锁(two-phase locking)
如果事务A已经读取了某个对象,此时事务B想要写入该对象,那么B必须等到A提交或中止之才能继续。以确保B不会在事务A执行的过程中间去修改对象。
如果事务A已经修改了对象,此时事务B想要读取该对象,则B必须等到A提交或中止之后才能继续。对于2PL,不会出现读到旧值的情况。
实现两阶段加锁
目前,2PL已经用于MySQL(InnoDB)和SQLServer中的“可串行化隔离”,以及DB2中的“可重复读隔离”。
此时数据库的每个对象都有一个读写锁来隔离读写操作。即锁可以处于共享模式或独占模式:
- 如果事务要读取对象,必须先以共享模式获得锁。可以有多个事务同时获得一个对象的共享锁,但是如果某个事务已经获得了对象的独占锁,则所有其他事务必须等待。
- 如果事务要修改对象,必须以独占模式获取锁。不允许多个事务同时持有锁(包括共享或独占模式),换言之,如果对象上已被加锁,那么修改事务必须等待。
- 如果事务首先读取对象,然后尝试写入对象,则需要将共享锁升级为独占锁。升级锁的流程等价于直接获得独占锁。
- 事务获得锁之后,一直持有锁直到事务结束(包括提交或中止)。
这也是名字“两阶段”的来由,在第一阶段即事务执行之前要获取锁,第二阶段(即事务结束时)则释放锁。
锁过多会导致的问题:死锁
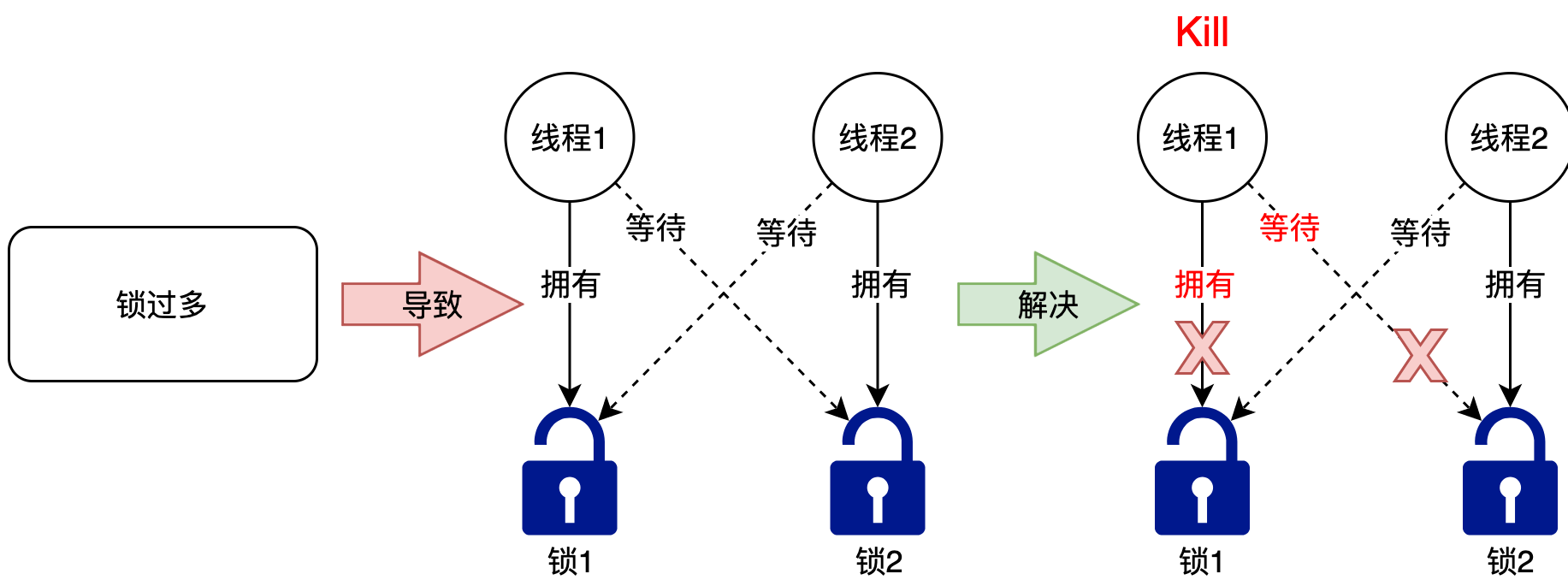 数据库系统会自动检测事务之间的死锁情况,并强行中止其中的一个以打破僵局,这样另一个可以继续向前执行。
数据库系统会自动检测事务之间的死锁情况,并强行中止其中的一个以打破僵局,这样另一个可以继续向前执行。
但我们需要考虑的问题是:僵局打破后,线程1的数据就应该丢掉吗?应用层是否需要做重试?
两阶段加锁升级版
| 谓词锁 | 索引区间锁 | |
|---|---|---|
| 功能介绍 | 它的作用类似于之前描述的共享/独占锁,而区别在于,它并不属于某个特定的对象(如表的某一行),而是作用于满足某些搜索条件的所有查询对象。谓词锁会限制如下访问: 如果事务A想要读取某些搞足匹配条件的对象,例如采用SELECT查询,它必须以共享模式获得查询条件的谓词锁。 如果另一个事务B正持有任何一个匹配对象的互斥锁,那么A必须等到B释放锁之后才能继续执行查询。 如果事务A想要插入、更新或删除任何对象,则必须首先检查所有旧值和新值是否与现有的任何谓词锁匹配(即冲突)。如果事务B持有这样的谓词锁,那么A必须等到B完成提交(或中止)后才能继续。 |
本质上它是对谓词锁的简化或者近似,简化谓词锁的方式是将其保护的对象扩大化,首先这肯定是安全的。 |
| 优点 | 这里的关键点在于, 谓词锁甚至可以保护数据库中那些尚不存在但可能马上会被插入的对象(幻读)。 | 相比较于谓词锁,开销低得多。 |
| 缺点 | 性能不佳:如果活动事务中存在许多锁,那么检查匹配这些锁就变得非常耗时。 | 索引区间锁不像谓词锁那么精确,定更大范围的对象,而超出了串行化所要求的部分。 |
| 备注 | 如果没有合适的索引可以施加区间锁,则数据库可以回退到对整个表加锁。这种方式的性能肯定不好,它甚至会阻止所有其他事务的写操作,但的确可以保证安全性。 |
3.可串行化的快照隔离(Serializable Snapshot Isolation,SSI)
悲观与乐观的并发控制
两阶段加锁是一种典型的悲观井发控制机制
为了提供可串行化的快照隔离,数据库必须检测事务是否会修改其他事务的查询结果,并在此情况下中止写事务。
数据库如何知道查询结果是否发生了改变呢?可以分以下两种情况:
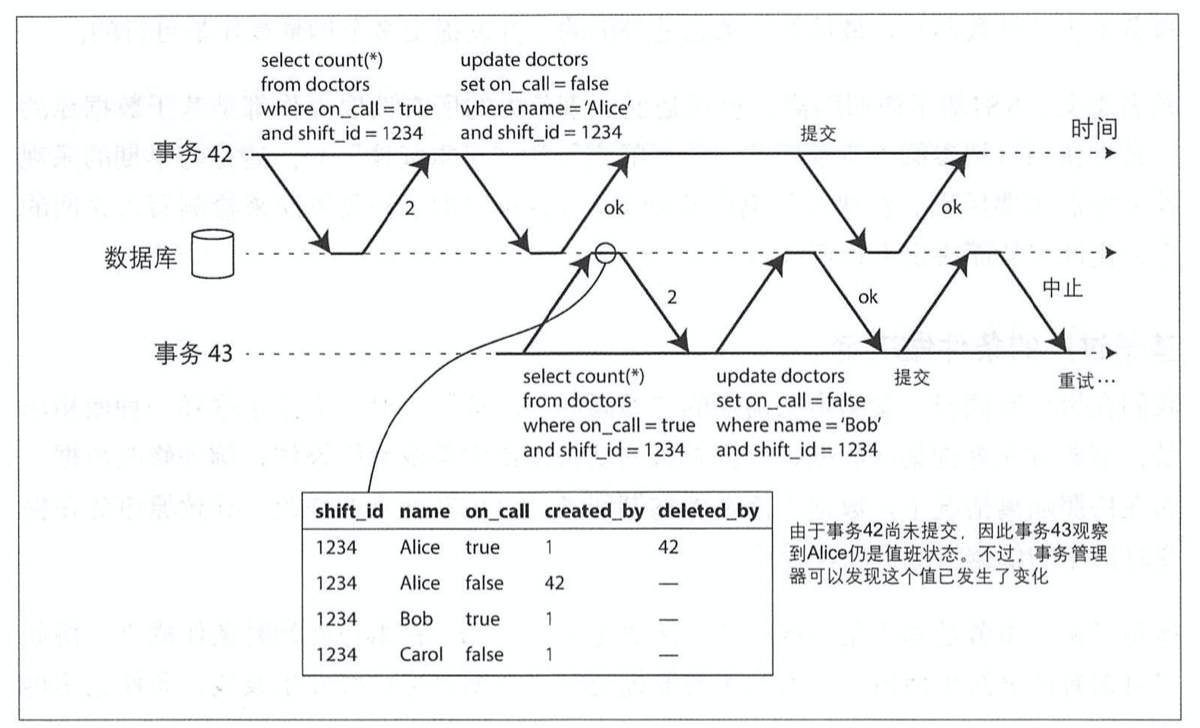
- 读取是否作用于一个(即将)过期的MVCC对象(读取之前已经有未提交的写入)。
- 检查写人是否影响即将完成的读取(读取之后,又有新的写入)。
| 检测是否读取了过期的 MVCC对象 | 检测写是否影晌了之前的读 |
|---|---|
 |
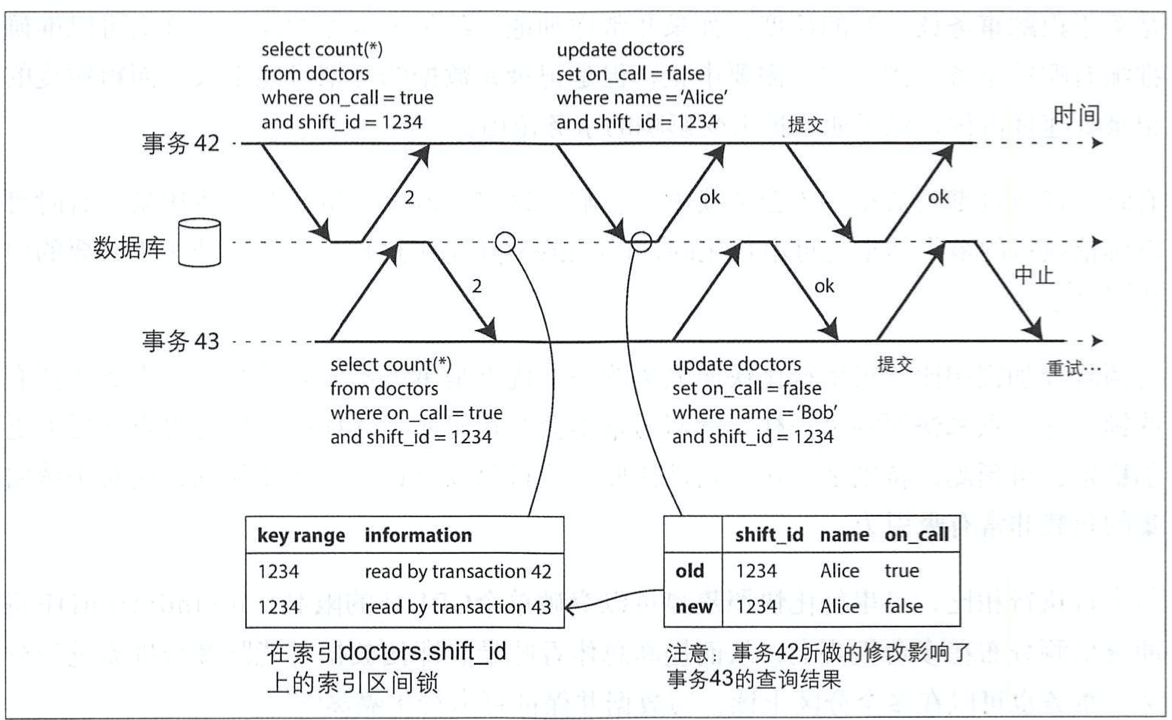 |
| 为什么要等到提交: 当检测到读旧值,为何不立即中止事务43呢? 如果事务43是个只读事务,没有任何写倾斜风险,就不需要中止。 事务提交时,有可能事务42发生了中止或者还处于未提交状态,因此读取的并非是过期值。 |
1.事务42和事务43都在查询轮班 1234期间的值班医生。数据库可以通过索引条目1234来记录事务42和事务43都查询了相同的结果。该额外记录只需保留很小一段时间,当并发的所有事务都处理完成(提交或中止)之后,就可以丢弃。 2.当另一个事务尝试修改时,它首先检查索引,从而确定是否最近存在一些读目标数据的其他事务。这个过程类似于在受影响的宇段范围上获取写锁,但它并不会阻塞读取,而是直到读事务提交时才进一步通知他们 : 所读到的数据现在已经发生了变化。 3.事务43和事务42会互相通知对方先前的读已经过期。虽然事务43的修改的确影响了事务42,但事务43当时并未提交(修改未生效), 而事务42首先尝试提交,所以可以成功;随后当事务43试图提交时,来自事务42的冲突写已经提交生效,事务43不得不中止。 |
串行化快照隔离的优点是什么:
- 与两阶段加锁相比,可串行化快照隔离事务不需要等待其他事务所持有的锁。这一点和快照隔离一样 ,读写通常不会互相阻塞。
- 与严格串行执行相比,可串行化快照隔离可以突破单个CPU核的限制。
- 这样的设计使得查询延迟更加稳定、可预测。
- 在一致性快照上执行只读查询不需要任何锁,这对于读密集的负载非常有吸引力。
防止更新丢失
更新丢失发生的场景:
应用程序从数据库读取某些值,根据应用逻辑做出修改,然后写回新值。
即:read-modify-write
更新丢失常见的解决方案
| 解决方案 | 示例 |
|---|---|
| 原子写操作 | UPDATE counters SET value = value + 1 WHERE key = "foo"; |
| 显式加锁 | SELECT * FROM student WHERE name = 'zhangsan' FOR UPDATE; |
| 原子比较和设置 | UPDATE wiki SET content = 'new_content' WHERE id = 1234 AND content = 'old_content'; |
| 自动检测更新丢失 | 数据库完全可以借助快照级别隔离来高效地执行检查(SSI)。 但是MySQL/InnoDB的可重复读并不支持检测更新丢失 |
Q:第三点CAS可靠吗?应用层是不是需要兼容?
A:不可靠,如果update失败,则应用层不能盲目的将新数据丢弃,而是应该检测冲突并解决。【或告知用户,本次更新操作存在冲突,需要重新提交】
总结
| 问题 | 详细解释 | 解决方案 |
|---|---|---|
| 脏写 | 客户端覆盖了另一个客户端尚未提交的写入。 | 几乎所有的数据库实现都可以防止脏写。 |
| 脏读 | 客户端读到了其他客户端尚未提交的写人。 | 读-提交以及更强的隔离级别可以防止脏读 。 |
| 读倾斜(不可重复读) | 客户在不同的时间点看到了不同值。 | 可重复读(快照隔离)是最用的防范手段, 即事务总是在某个时间点的一致性快照中读取数据。通常采用多版本井发控制( MVCC )来实现快照隔离。 |
| 幻读 | 事务读取了某些符合查询条件的对象,同时另一个客户端执行写入,改变了先前的查询结果。 | 快照隔离可以防止简单的幻读(只读查询)。 |
| 写倾斜 | 事务首先查询数据,根据返回的结果而作出某些决定,然后修改数据库 。当事务提交时,支持决定的前提条件已不再成立。 | 只有可串行化的隔离才能防止这种异常。 |
| 更新丢失 | 两个客户端同时执行【读-修改-写入】操作,出现了其中一个覆盖了另一个的写入,但又没有包含对方最新值的情况,最终导致了部分修改数据发生了丢失。 | 快照隔离的一些实现(SSI)可以自动防止这种异常。或手动锁定查询结果(SELECT FOR UPDATE)。 |